This is the fourth post in theStandard Parallel Programmingseries, which aims to instruct developers on the advantages of using parallelism in standard languages for accelerated computing:
- Developing Accelerated Code with Standard Language Parallelism
- Multi-GPU Programming with Standard Parallel C++, Part 1
- Multi-GPU Programming with Standard Parallel C++, Part 2
Standard languages have begun adding features that compilers can use for accelerated GPU and CPU parallel programming, for instance,do concurrentloops and array math intrinsics inFortran.
Using standard language features has many advantages to offer, the chief advantage being future-proofness. As Fortran’sdo concurrentis a standard language feature, the chances of support being lost in the future is slim.
This feature is also relatively simple to use in initial code development and it adds portability and parallelism. Usingdo concurrentfor initial code development has the mental advantage of encouraging you to think about parallelism from the start as you write and implement loops.
For initial code development,do concurrentis a great way to add GPU support without having to learn directives. However, even code that has already been GPU-accelerated through the use of directives likeOpenACCandOpenMPcan benefit from refactoring to standard parallelism for the following reasons:
- Cleaning up the code for those who do not know directives, or removing the large numbers of directives that make the source code distracting.
- Increasing the portability of the code in terms of vendor support and longevity of support.
- Future-proofing the code, as ISO-standard languages have a proven track record for stability and portability.
Replacing directives on multi-core CPUs and GPUs
POT3D is a Fortran code that computes potential field solutions to approximate the solar coronal magnetic field using surface field observations as input. It continues to be used for numerous studies of coronal structure and dynamics.
The code is highly parallelized usingMPIand is GPU-accelerated using MPI with OpenACC.It is open source and available on GitHub. It is also a part of theSpecHPC 2021 Benchmark Suites.
We recentlyrefactored another code example with do concurrentatWACCPD2021. The results showed that you could replace directives withdo concurrentwithout losing performance on multicore CPUs and GPUs. However, that code was somewhat simple in that there is no MPI.
Now, we want to explore replacing directives in more complicated code. POT3D contains nontrivial features for standard Fortran parallelism to handle: reductions, atomics,CUDA-aware MPI, and local stack arrays. We want to see ifdo concurrentcan replace directives and retain the same performance.
To establish a performance baseline for refactoring the code todo concurrent, first review the initial timings of the original code in Figure 1. The CPU result was run on 64 MPI ranks (32 per socket) on a dual-socket AMD EPYC 7742 server, while the GPU result was run on one MPI rank on anNVIDIA A100(40GB). The GPU code relies on data movement directives for data transfers (we do not use managed memory here) and is compiled with-acc=gpu -gpu=cc80,cuda11.5. The runtimes are an average over four runs.
The following highlighted text shows the number of lines of code and directives for the current version of the code. You can see that there are 80 directives, but we hope to reduce this number by refactoring withdo concurrent.
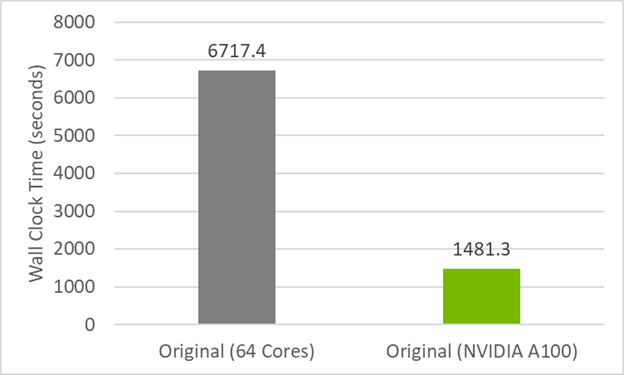
Figure 1. CPU and GPU timings for the original version of the POT3D code show substantial improvement on wall clock time for the original code when using OpenACC on an NVIDIA A100 40GB GPU
| POT3D (Original) | |
|---|---|
| Fortran | 3,487 |
| Comments | 3,452 |
| OpenACC Directives | 80 |
| Total | 7,019 |
Table 1. Code facts for POT3D including Fortran, comments, OpenACC Directives, and total lines.
Do concurrent and OpenACC
Here are some examples ofdo concurrentcompared to OpenACC from the code POT3D, such as a triple-nested OpenACC parallelized loop:
As mentioned earlier, this OpenACC code is compiled with the flag-acc=gpu -gpu=cc80,cuda11.5to run on an NVIDIA GPU.
You can parallelize this same loop with doconcurrentand rely onNVIDIA CUDA Unified Memoryfor data movement instead of directives. This results in the following code:
As you can see, the loop has been condensed from 12 lines to three, and CPU portability and GPU parallelism are retained with the nvfortran compiler from theNVIDIA HPC SDK.
This reduction in the number of lines is thanks to collapsing multiple loops into one loop and relying on managed memory, which removes all data movement directives. Compile this code for the GPU with-stdpar=gpu -gpu=cc80,cuda11.5.
For nvfortran, activating standard parallelism (-stdpar=gpu) automatically activates managed memory. To use OpenACC directives to control data movement along withdo concurrent, use the following flags:-acc=gpu -gpu=nomanaged.
The nvfortran implementation ofdo concurrentalso allows for locality of variables to be defined:
This may be necessary for some code. For POT3D, the default locality of variables performs as needed. The default locality is the same as OpenACC with nvfortran.
do concurrent CPU performance and GPU implementation
Replacing all the OpenACC loops withdo concurrentand relying on managed memory for data movement leads you to code with zero directives and fewer lines. We removed 80 directives and 66 lines of Fortran.
Figure 2 shows that thisdo concurrentversion of the code has nearly the same performance on the CPU as the original GitHub code. This means that you haven’t broken CPU compatibility by using do concurrent. Instead, multi-core parallelism has also been added, which can be used by compiling with the flag-stdpar=multicore.
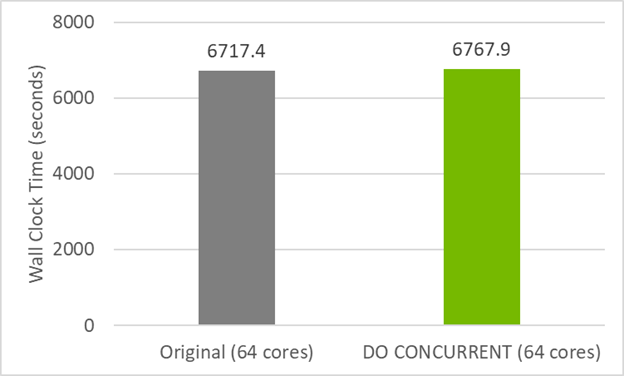
Figure 2. CPU timings using MPI (32 ranks per socket) for the original anddo concurrentversions of the POT3D code
Unlike the case of the CPU, to be able to run POT3D on a GPU, you must add a couple of directives.
First, to take advantage of multiple GPU with MPI, you need a directive to specify the GPU device number. Otherwise, all MPI ranks would use the same GPU.
In this example, mpi_shared_rank_numis the MPI rank within a node. It’s assumed that the code is launched such that the number of MPI ranks per node is the same as the number of GPUs per node. This can also be accomplished by settingCUDA_VISIBLE_DEVICESfor each MPI rank, but we prefer doing this programmatically.
When using managed memory with multiple GPUs, make sure that the device selection (such as!$acc set device_num(N)) is done before any data is allocated. Otherwise, an additional CUDA context is created, introducing additional overhead.
Currently, the nvfortran compiler does not support array reductions on concurrent loops, which are required in two places in the code. Fortunately, an OpenACC atomic directive can be used in place of an array reduction:
After adding this directive, change the compiler options to enable OpenACC explicitly by using-stdpar=gpu -acc=gpu -gpu=cc80,cuda11.5. This allows you to use only three OpenACC directives. This is the closest this code can come to not having directives at this time.
All the data movement directives are unnecessary, since CUDA managed memory is used for all data structures. Table 2 shows the number of directives and lines of code needed for this version of POT3D.
| POT3D (Original) | POT3D (Do Concurrent) | Difference | |
|---|---|---|---|
| Fortran | 3487 | 3421 | (-66) |
| Comments | 3452 | 3448 | (-4) |
| OpenACC Directives | 80 | 3 | (-77) |
| Total | 7019 | 6872 | (-147) |
Table 2. Number of lines of code for the GPU compatibledo concurrentversion of POT3D with a breakdown of the number of Fortran lines, directives, and comments lines.
For the reduction loops in POT3D, you relied on implicit reductions, but that may not always work. Recently, nvfortran has added the upcoming Fortran 202X reduce clause, which can be used on reduction loops as follows:
GPU performance, unified memory, and data movement
You’ve developed code with the minimal number of OpenACC directives anddo concurrentthat relies on managed memory for data movement. This is the closest directive-free code that you can have at this time.
Figure 3 shows that this code version takes a small performance hit of ~10% when compared to the original OpenACC GPU code. The cause of this could bedo concurrent,managed memory, or a combination.
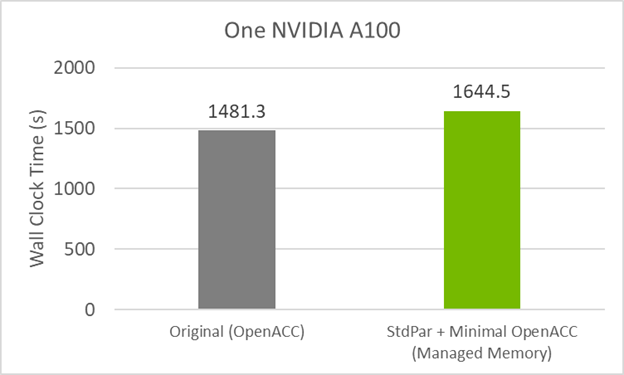
Figure 3. GPU timings for the GitHub and standard parallelism (STDPAR) with minimal OpenACCversions of the POT3D code on one NVIDIA A100 40GB GPU.
To see if managed memory causes the small performance hit, compile the original GitHub code with managed memory turned on. This is done by using the compile flag-gpu=managedin addition to the standard OpenACC flags used before for the GPU.
Figure 4 shows that the GitHub code now performs similar to the minimum directives code with managed memory. This means that the culprit for the small performance loss is unified memory.
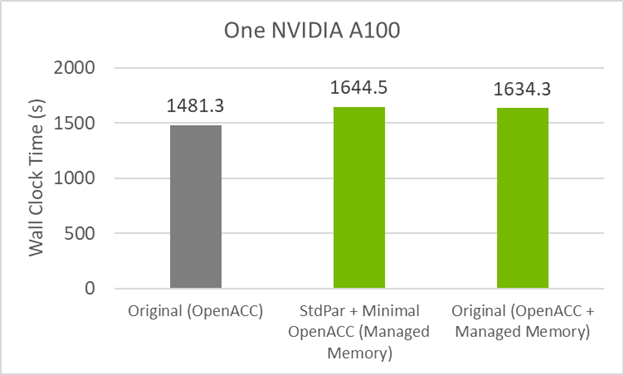
Figure 4. GPU timings for the GitHub (managed and no managed) and STDPAR with minimal OpenACCversions of the POT3D code.
To regain the performance of the original code with the minimal directives code, you must add the data movement directives back in. This mixture ofdo concurrentand data movement directives would look like the following code example:
This results in the code having 41 directives, with 38 being responsible for data movement. To compile the code and rely on the data movement directives, run the following command:
-stdpar=gpu -acc=gpu -gpu=cc80,cuda11.5,nomanaged
nomanagedturns off managed memory and-acc=gputurns on the directive recognition.
Figure 5 shows that there is nearly the same performance as the original GitHub code. This code has 50% fewer directives than the original code and gives the same performance!
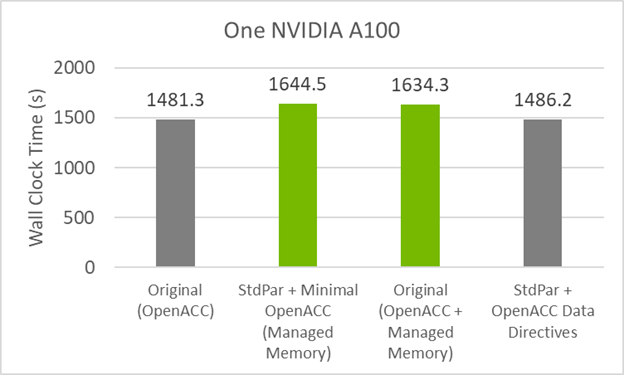
Figure 5. GPU timings for the GitHub (managed and no managed), STDPAR + minimal OpenACC (managed), and STDPAR + OpenACC (no managed)versions of the POT3D code.
MPI + DO CONCURRENT scaling
Figure 7 shows the timing results using multiple GPUs. The primary takeaway is thatdo concurrentworks with MPI over multiple GPUs.
Looking at the codes with managed memory turned on (blue lines), you can see that the original code and the minimal directives code gave nearly the same performance as multiple GPUs were used.
Looking at the codes with managed memory turned off (green lines), you can again see the same scaling between the original GitHub code and thedo concurrentversion of the code. This indicates thatdo concurrentworks with MPI and has no impact on the scaling you should see.
What you might also notice is that managed memory causes an overhead as the GPUs are scaled. The managed memory runs (blue lines) and data directive lines (green lines) are parallel to each other, meaning the overhead scales with the number of GPUs.
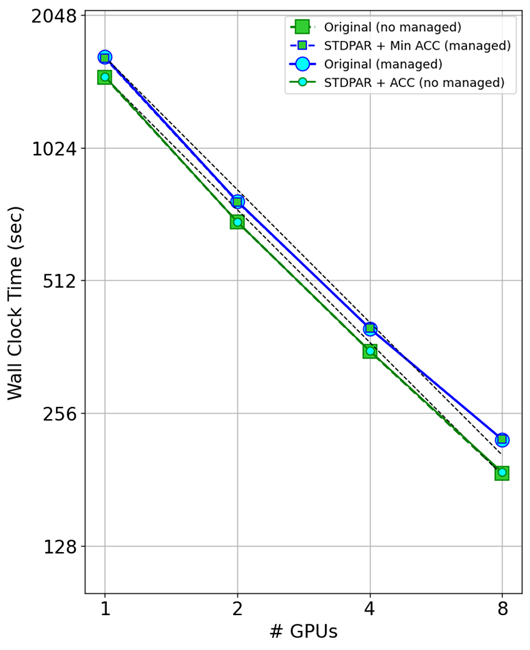
Figure 6. GPU scaling across 1, 2, 4, and 8 GPUs for the GitHub (managed and no managed), STDPAR + minimal OpenACC (managed), and STDPAR + OpenACC (no managed)versions of the POT3D code.
Fortran standard parallel programming review
You may be wondering, “Standard Fortran sounds too good to be true, what is the catch?”
Fortran standard parallel programming enables cleaner looking code and increases the future proofness of your code by relying on ISO language standards. Using the latest nvfortran compiler, you gain all the benefits mentioned earlier.
Although you lose the current GCC OpenACC/MP GPU support when you transition todo concurrent, we expect to gain more GPU support in the future as other vendors add support ofdo concurrenton GPUs. Given the track record of ISO language standards, we believe that this support will come.
Usingdo concurrentdoes currently come with a small number of limitations, namely the lack of support for atomics, device selection, asynchrony, or optimizing data movement. As we have shown, however, each of these limitations can be easily worked around using compiler directives. Far fewer directives are required thanks to the native parallel language features in Fortran.
Ready to get started?Download the free NVIDIA HPC SDK, and start testing! If you are also interested in more details on our findings, see theFrom Directives to DO CONCURRENT: A Case Study in Standard ParallelismGTC session. For more information about standard language parallelism, seeDeveloping Accelerated Code with Standard Language Parallelism.
Acknowledgments
This work was supported by the National Science Foundation, NASA, and the Air Force Office of Scientific Research. Computational resources were provided by the Computational Science Resource Center at San Diego State University.