The NVIDIA platform is the most mature and complete platform for accelerated computing. In this post, I address the simplest, most productive, and most portable approach to accelerated computing. There are three approaches that you can take for programming GPUs (Figure 1).
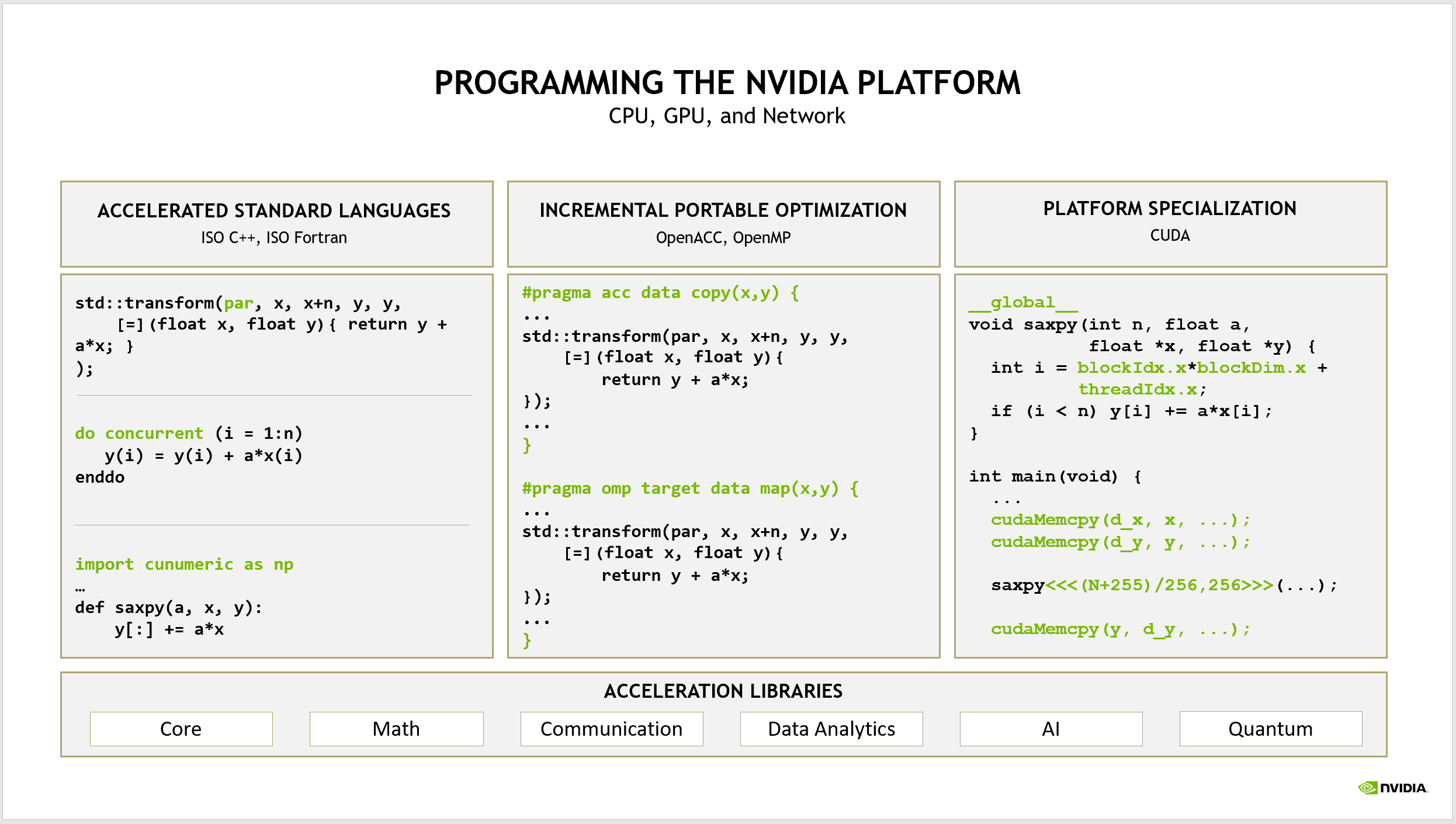
Figure 1. Three approaches to programming the NVIDIA platform
CUDA C++andFortranare the innovation ground where NVIDIA can expose new hardware and software innovations, and where you can tune your applications to achieve the best possible performance on NVIDIA GPUs. Many developers assume that this is how NVIDIA expects everyone to program for GPUs.
Instead, we expect that developers coming to the NVIDIA platform for the first time will use standard, parallel programming languages, such as ISO C++, ISO Fortran, and Python. In this post, I highlight some successes in using this approach to parallel programming to demonstrate the most productive path to entering the NVIDIA CUDA ecosystem.
The foundation of the NVIDIA strategy is providing a rich, mature set of SDKs and libraries on which applications can be built. NVIDIA already provides highly tuned math libraries, such ascuBLAS,cuSolver, andcuFFT; core libraries, such asThrustandlibcu++; and communication libraries, such asNCCLandNVSHMEM, as well as other packages and frameworks on which you can build your applications.
On top of this, NVIDIA layers the three different programming approaches:
- Standard language parallelism, which is the subject of this post
- Languages for platform specialization, such as CUDA C++ and CUDA Fortran for obtaining the best possible performance on the NVIDIA platform
- Compiler directives, bridging the gap between these two approaches by enabling incremental performance optimization
Each of these approaches makes tradeoffs in terms of performance, productivity, and code portability. As they can all interoperate, you don’t have to use a particular model but can mix any or all as desired.
If you start writing code using parallelism in standard programming languages, then you can come to the NVIDIA platform or any other platform with baseline code that is already capable of running in parallel. This is why we have invested more than a decade collaborating in the standard language committees on the adoption of features to enable parallel programming without the need for additional extensions or APIs. Standard language parallelism is a rising tide that raises all boats.
ISO C++
The C++ programming language is consistently among the top programming languages in recent studies of programming trends. It has seen a significant increase in usage in scientific computing. The richness of its Standard Template Library makes it a highly productive language for new code development and, since the release of C++17, it has supported several important features for parallel programming.
I’ve seen several applications get refactored away from traditional for loops in favor of these C++ parallel algorithms. Here are the results from a few of them.
Lulesh
Lulesh is a hydrodynamics mini-app from Lawrence Livermore National Laboratory (LLNL), written in C++. The mini-app has several versions for evaluating different programming approaches, both in terms of the quality of the code and performance. We worked with the developers to rewrite their existing OpenMP-based code to use C++ Parallel Algorithms. Figure 2 shows an example of just one of the application’s important functions.

Figure 2. Refactoring Lulesh from OpenMP to ISO C++ parallelism results in code that is simpler, easier to read, ISO standard, and portable to all compilers that support ISO C++
The code on the left uses OpenMP to parallelize the loops in the code across CPU threads. To maintain both a serial and parallel version of the code, the developers used#ifdefmacros and compiler pragmas. The result is repeated code and the introduction of an additional API, OpenMP, into the source.
The code on the right is the same routine, but rewritten using the C++transform_reducealgorithm. The resulting code is much more compact, making it less error prone, easier to read, and more maintainable. It also removes the dependency on OpenMP, relying instead on the C++ standard template library, while maintaining a single source code for all platforms. This code is fully ISO C++ compliant, capable of being built by any C++ compiler that supports C++17. As it turns out, it is faster too!
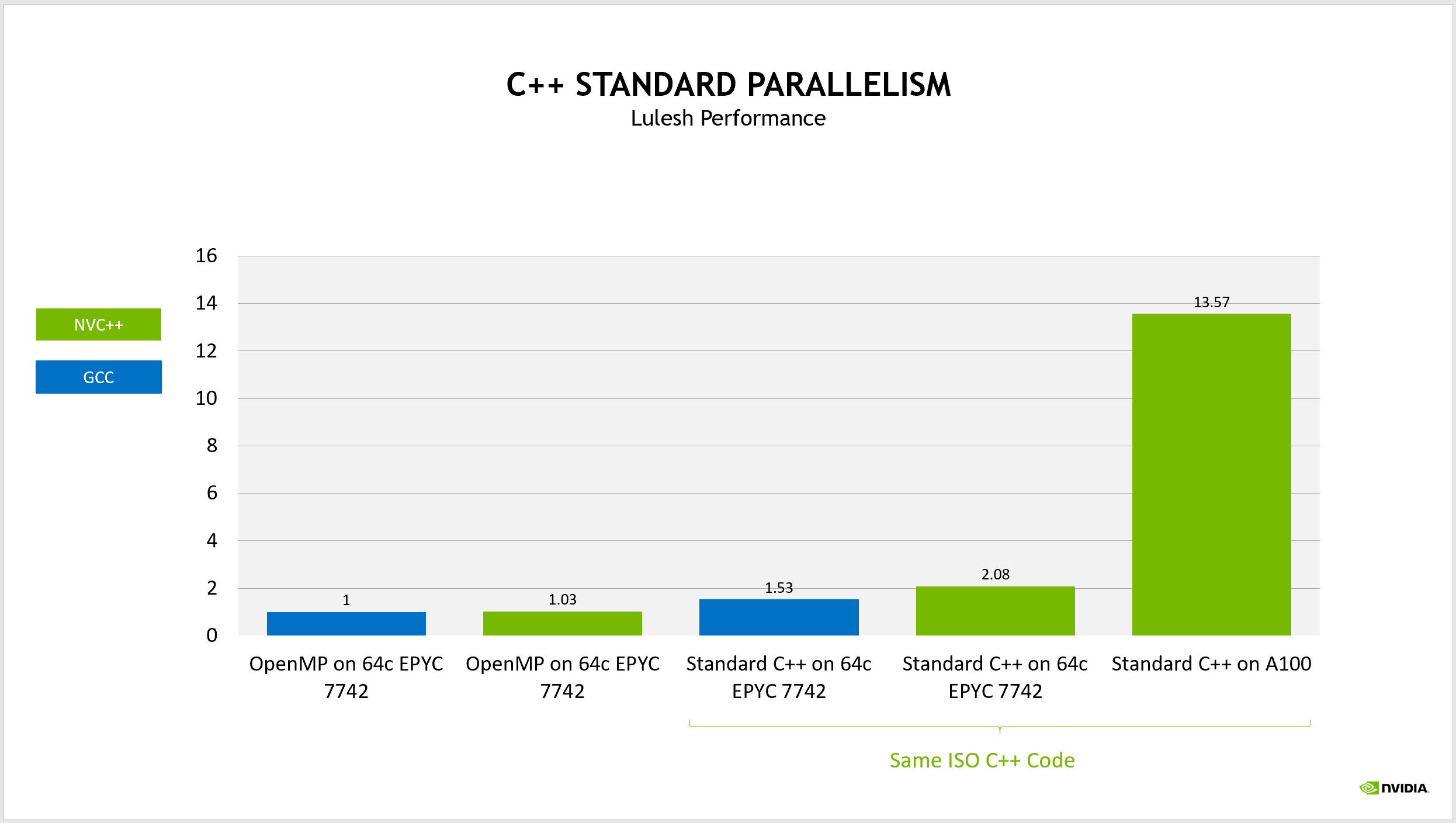
Figure 3. The ISO C++ version of Lulesh is faster than the original OpenMP code and portable to multiple compilers and between the CPU and GPU
As a performance baseline, we used the OpenMP code running on all cores of an AMD EPYC 7742 processor and built with GCC. Rebuilding this baseline code using NVIDIAnvc++compiler achieves essentially the same performance on the CPU.
If you instead build the ISO C++ code using the same version of GCC and running on the same CPU, the performance improves by roughly 50%, due to various improved overheads and opportunities for the compiler to better optimize the code.
This turns into a 2X performance improvement when building this code usingnvc++and running on the same CPU. This is already an exciting achievement but to top that off, you can build this same code, changing only a compiler option to target an NVIDIA GPU instead of a multicore CPU. Now that same code runs more than 13X faster by running on an NVIDIA A100 GPU. There’s a 13.5X performance improvement from the original code, running in parallel both on the CPU and GPU, using strictly ISO C++ code.
STLBM
Another example of an application using C++ Standard Parallelism is STLBM, a Lattice-Boltzmann solver from the University of Geneva. Professor Jonas Latt discussed this application in several GTC sessions, showing how code written in ISO C++ without any external SDK dependencies can run with multiple compilers and on multiple hardware platforms, including NVIDIA GPUs. For more information, seeFluid Dynamics on GPUs with C++ Parallel Algorithms: State-of-the-Art Performance through a Hardware-Agnostic ApproachandPorting a Scientific Application to GPU Using C++ Standard Parallelism
His application achieves more than a 12X performance improvement using GPUs. What is notable is that his baseline for comparison is a source code that is parallel by default, using the parallel algorithms in the C++17 standard template library to express the parallelism inherent in the application.
He categorized the experience of using ISO C++ to program for GPUs as“a paradigm shift in cross-platform CPU/GPU programming.” Rather than writing an application that is serial by default and then adding parallelism later, his team has written an application that is ready for any parallel platform on which they wish to run.
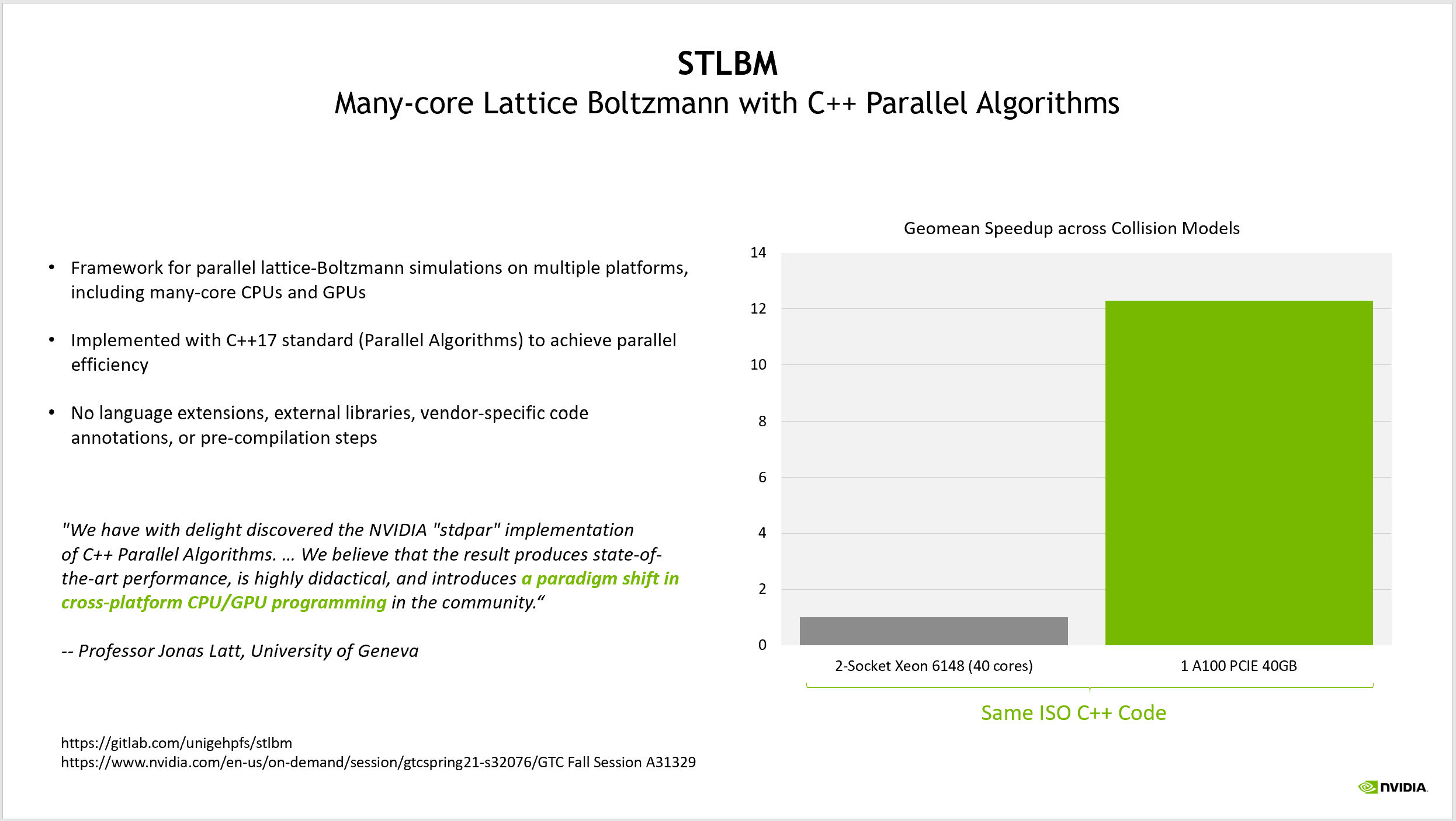
Figure 4. STLBM is capable of running the same source code on multicore CPU nodes and on NVIDIA GPUs
NVIDIA is heavily invested in the continued development of parallelism and concurrency in C++ and has coauthored a variety of proposals for the upcoming C++23 specification to further improve your ability to write code that is parallel-first.
ISO Fortran
Fortran remains a language whose primary focus is on scientific and high performance computing. Originally, the FORmula TRANslator, Fortran provides a variety of advantages both to developers and compilers, and also has a huge existing code base for modeling and simulation codes.
Fortran began adding features to support parallel programming in Fortran 2008, enhanced these capabilities in Fortran 2018, and continues to refine them in the upcoming version, currently referred to as Fortran 202X. Just as with ISO C++, NVIDIA has been working with application developers to use standard language parallelism in Fortran to modernize their applications and make them parallel-first.
Computational chemistry
My colleague Jeff Hammond, in hisFortranCon2021: Standard Fortran on GPUs and its utility in quantum chemistry codessession, presented some promising results using Fortrando concurrentloops in kernels taken from the NWChem application and also GAMESS, another computational chemistry application.
For NWChem, he isolated several performance-critical loops that perform tensor contractions and has written them using several programming models. On multicore CPUs, these tensor contractions use OpenMP for threading across CPU cores. For GPUs, there are versions available using OpenACC, OpenMP target offloading, and now Fortrando concurrentloops.
Figure 5 shows that thedo concurrentloops perform at the same level as both OpenACC and OpenMP target offloading on NVIDIA GPUs but without the need to include these additional APIs in the application. This is all standard Fortran.
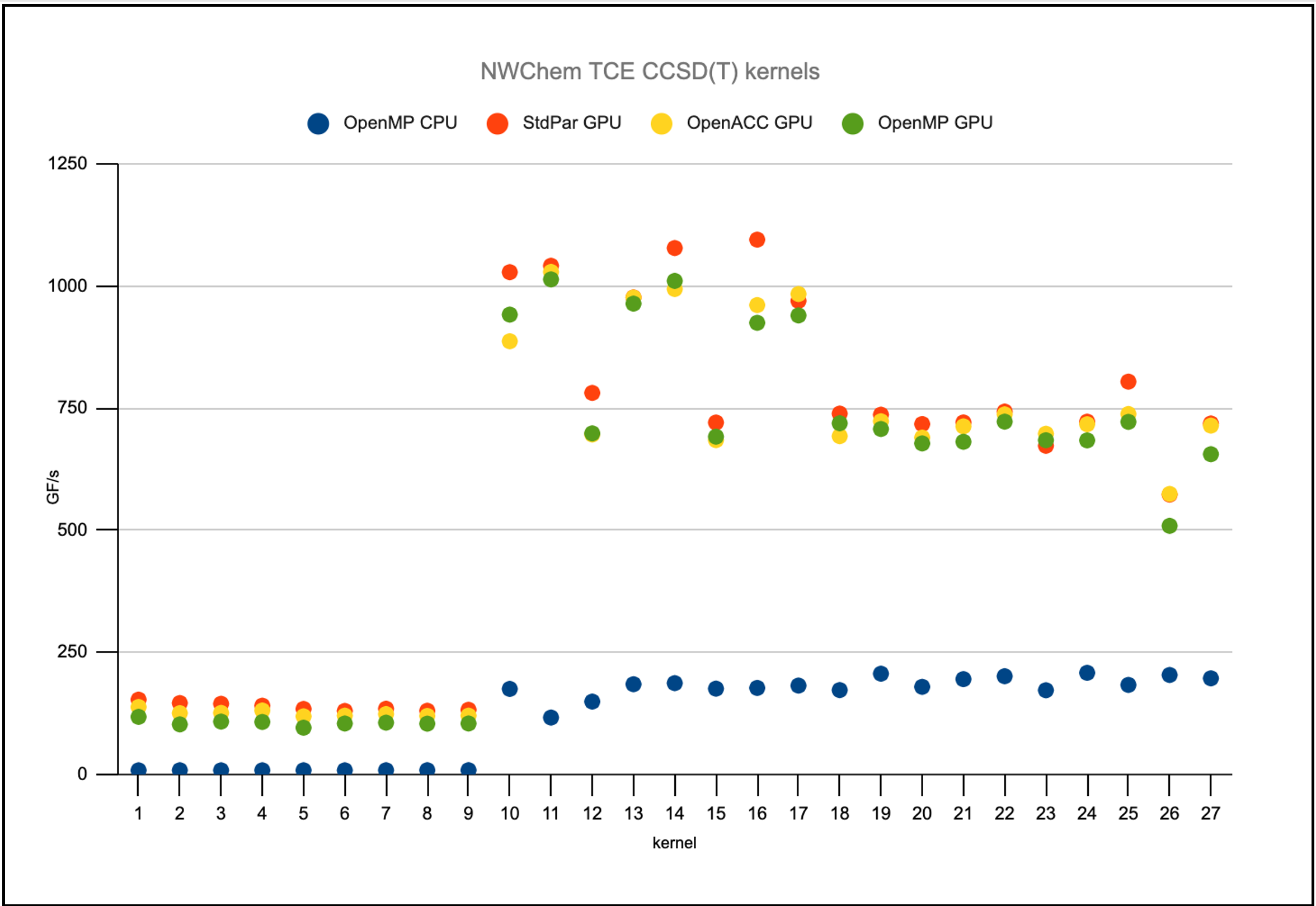
Figure 5 Performance of a range of NWChem application kernels using several programming models
High-performance flux transport
At the recent Workshop for Accelerator Programming Using Directives (WACCPD), collocated at the SC21 conference, a team of developers fromPredictive Science Inc.showed their results in refactoring one of their production codes, which previously used OpenACC to run on NVIDIA GPUs, usingdo concurrentloops.
They compared the results of building this purely ISO Fortran application using NVIDIAnvfortran,gfortran, andifort. They concluded that, for their application when using thenvfortrancompiler, pure Fortran gave the performance that they required without the need for any directives. Furthermore, this code could run in parallel on GPUs and multicore CPUs without modification.

Figure 6. Performance results for HipFT benchmark usingnvfortrancompiler
This paper received the award for best paper at the workshop, even though it required no directives at all for accelerator programming. When asked whether they would continue the standard language parallelism approach in their other applications, the presenter replied that they already have plans to adopt this approach in other important applications for their company.
Python with Legate and cuNumeric
The Python language has had a meteoric rise in popularity over the past decade. It is now commonly used in machine learning, data science, and even traditional modeling and simulation applications. Although Python is not an ISO programming language, like C++ and Fortran, we are implementing the spirit of standard language parallelism in the Python language as well.
In his keynote address at GTC’21 Fall, NVIDIA CEO Jensen Huang introduced the alpha release ofcuNumeric, a library that is modeled after NumPy and which enables features similar to what I have discussed for ISO C++ and Fortran. The NumPy package is so prevalent in Python development that it is a near certainty that any HPC application written in Python uses it.
ThecuNumericpackage, written on top of a package calledLegate, enables NumPy applications to automatically scale their work not only onto GPUs but across GPUs in a large cluster. I’ve seen for several example applications that simply replacing references to NumPy in the code to instead refer tocuNumeric, I could weakly scale that application to the full size of the NVIDIA internal cluster,Selene, which is among the 10 fastest supercomputers in the world.
For more information aboutcuNumeric, seeNVIDIA Announces Availability for cuNumeric Public Alphaand watch the GTC On-Demand session,Legate: Scaling the Python Ecosystem.
Conclusion
I hope this post has inspired you to see that GPU programming is not as difficult as you may have heard. If you use standard language parallelism, it may even be possible without any code changes at all.
NVIDIA is encouraging you to write applications parallel-first such that there is never a need to “port” applications to new platforms and standard language parallelism is the best approach to doing this, as it requires nothing more than the ISO standard languages. This is why we continue to invest in the ISO programming languages and in bringing even more features for parallelism and concurrency to these languages.
In summary, using standard language parallelism has the following benefits:
- Full ISO language compliance, resulting in more portable code
- Code that is more compact, easier to read, less error prone
- Code that is parallel by default, so it can run without modification on more platforms
Here are several talks from GTC’21 that can provide you with even more detail about this approach to parallel programming:
- Shifting through the Gears of GPU Programming: Understanding Performance and Portability Trade-offs
- Accelerated Computing with Standard C++, Python, and Fortran
- Legate: Scaling the Python Ecosystem
For more information, see the following resources:
- Learn more about the compiler support and other posts atHPC SDK.
- Download theHPC SDK softwarefor free.